

Galina recaps Evan’s April workshop on corpus analysis tools for business English teachers. She shares what she learned about data engines, the internet as a resource to find out about students’ real-life needs and ways to apply this knowledge in class.
This was a special ELTABB workshop for me, not only because of the unusual all-day format that allowed us to have a glimpse at several corpus analysis tools and play with them a little, but also because I had been looking forward to this workshop for over seven months and was honoured to be a scholarship winner.
The Conundrum of the Corpus
The first time I heard about the term ‘corpus’ was at one of our FTBE study group sessions back in 2017, when a group of daring ELTABB members were preparing for the First Certificate for Teachers of Business English. I have to confess, we didn’t have enough time to cover this topic, and I was thus left with a very vague idea of what it was and how it could be used.
Connecting the Dots
So what is a corpus? It’s a collection of texts, spoken or written, held in electronic format. Sounds not very impressing, right? How can a collection of texts be of much interest? What can we do with these electronic texts? Why bother analysing them?
I think all teachers at some point are faced with a question:
What should we teach and what do our students need the most?
That is exactly when corpus analysis tools come in handy by providing evidence instead of intuition, examples from real language use, as well as differentiating specific lexis.
Having come to the workshop prepared – with the required text documents and software downloaded and several online tools opened in our browsers, most of us still had not the slightest idea of the important terminology, such as KWIC (Key Word in Context), concordance, collocation, idiom principle, clusters/n-grams, keyword analysis. Evan led us through these terms, providing us with examples and giving us the opportunity to try them out using the online tools.
After mastering the terminology, we learned about the fascinating research that had been conducted, including Mike Nelson’s ‘Corpus-based study of the lexis of business English and business English teaching materials’, the ‘Language in the Workplace Project’ studying real interactions in New Zealand, as well as ABOT (American and British Office Talk Corpus) and CANBEC (Cambridge and Nottingham Business English Corpus).
Exploring Different Online Tools
After a short coffee break, we played a bit with online corpora:
SKELL https://www.sketchengine.eu/skell/
COCA https://www.english-corpora.org/coca/
HKCSE http://rcpce.engl.polyu.edu.hk/HKCSE/
Each of the above has its own advantages and disadvantages. While SKELL gives us a ‘taste’ of the Sketch Engine and is very good for searching collocations (the one I used the most after the workshop), COCA is a corpus of American English and very colourful and visual. HKCSE, however, is a corpus of spoken English.
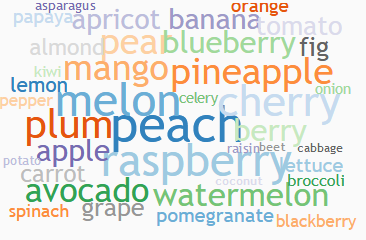
Before lunch, we managed to have a look at an offline corpus analysis tool – ‘Antconc’, which allows you to analyse any corpus you have. Evan let us work with the ‘EnronSent’ corpus that we downloaded beforehand. This is an email dataset which contains 2,205,910 lines and 13,810,266 words. It was when we started analysing the ‘EnronSent’ corpus that it became clear what a valuable tool for teaching business English it was with its fascinating examples of real life English, intertextuality and metaphors.
We took our impressions to lunch and spoke about ‘Enron letters’, how we could get our BE clients to share their data for us to analyse and why the results of corpora analysis were not used in course book writing as much as they deserved to be.
Using Corpora for our Teaching Practice
Lunch was followed by an overview of teaching activities one can create using corpus analysis tools such as: word clouds, gap-fills, language questions. Evan gave us some outstanding ideas and tips, e.g. using ‘cloze test creator’ to make gap-fill tasks online and how to answer unexpected questions like, “When do I say ‘looking forward’ and when do I say ‘going forward’?”, etc.
We finished the day playing with the new tools. While some just read the ‘Enron letters’, others tried to create materials for their classes. I decided to try to use my client’s website and created a couple of word clouds and gap-fills. We all agreed that for teachers, corpus analysis tools can be challenging but rewarding, and that investigating them might be time consuming but fascinating.
References:
- Handford, M. (2010). The Language of Business Meetings. Cambridge: Cambridge University Press.
- Holmes, J. (2006). Gendered talk at work. Oxford: Blackwell Publishing.
- Holmes, J. and Stubbe, M. (2003). Power and Politeness in the Workplace. London: Pearson Education.
- Koester, A. (2010). Workplace Discourse. London: Continuum.
- Leber, J. (2013). The immortal life of the Enron e-mails.
- Styler, W. (2011). The EnronSent.
- Nelson, M. (2000). A Corpus-based Study of Business English and Business English Teaching Materials, PhD thesis, University of Manchester. (retrievable from his website)
- O’Keeffe, A., McCarthy, M., & Carter, R. (2007). From Corpus to Classroom: language use and language teaching, Cambridge: Cambridge University Press.
- Sinclair, J. (1991). Corpus, concordance, collocation. Oxford: Oxford University Press.
- Vine, B. (2004). Getting Things Done at Work: The Discourse of Power in Workplace Interaction. Amsterdam and Philadelphia: John Benjamins.
Want to read more from Galina? She shares a funny teaching story here.







